
Bem-vindo ao meu blog A postagem de hoje é um pouco diferente, foi escrita por mim, no entanto, o artigo original foi publicado no DeliveryHero Techblog.
Confira o artigo original clicando aqui.
Boa leitura.
Desafiamos as equipes de tecnologia a testar uma longa interrupção de um aplicativo de configuração em um ambiente de produção por uma hora sem perder nenhuma solicitação usando Chaos Engineering. E adivinhe só? Conseguimos!
Como chegamos até aqui?
Nos últimos meses, nossa equipe embarcou em um experimento empolgante e desafiador de engenharia do caos. Nosso objetivo era simples: entender o comportamento de nossos serviços e garantir a operação segura de nossos aplicativos no caso de uma interrupção prolongada de um aplicativo de terceiros. Os resultados foram surpreendentes e temos o orgulho de compartilhar nossas descobertas com você nesta publicação do blog!
As a company that serves millions of users worldwide, we understand the importance of proactively identifying weaknesses in our complex systems. That’s why we follow in the footsteps of tech giants like Google, Amazon and Netflix, adopting chaos engineering experiments to ensure reliability and resilience.
In previous years, our platform experienced lost orders due to issues related to feature and configuration flags. Determined to address these issues, we challenged our technology product line leaders to test a long outage of a configuration application in a production environment for one hour without losing any orders. And guess what? We did it!
A experiência: Mergulhar no caos para reforçar as aplicações
Já alguma vez se perguntou como é que as empresas de tecnologia gerem e testam novas funcionalidades nas suas aplicações antes de as disponibilizarem aos utilizadores finais? Ou mesmo como cada ambiente tem sua configuração específica de acordo com a localização? Uma das práticas mais comuns é o uso de sistemas de gerenciamento de bandeiras de funcionalidades. Neste experimento, exploramos como o uso da Chaos Engineering pode melhorar a resiliência de todo um ecossistema que utiliza uma aplicação de terceiros para configuração e/ou disponibilidade.
Chaos Engineering é uma abordagem sistemática para melhorar a resiliência e a confiabilidade de um sistema por meio da introdução de falhas e distúrbios controlados em ambientes específicos. Essa prática ajuda a identificar e resolver problemas antes que eles causem interrupções indesejadas, garantindo assim que o sistema possa lidar e se adaptar a diferentes cenários de falha.
Dessa forma, as equipes podem aprender como os sistemas reagem sob pressão e melhorar sua capacidade de recuperação ao enfrentar eventos adversos, usando a ferramenta para reduzir o raio de explosão. Alguns exemplos podem ser a execução de testes na produção durante as horas de baixo tráfego, a realização de experimentos em ambientes de preparação e a realização de experimentos em uma porcentagem específica de instâncias de aplicativos.
O desafio: Colocar o sistema à prova
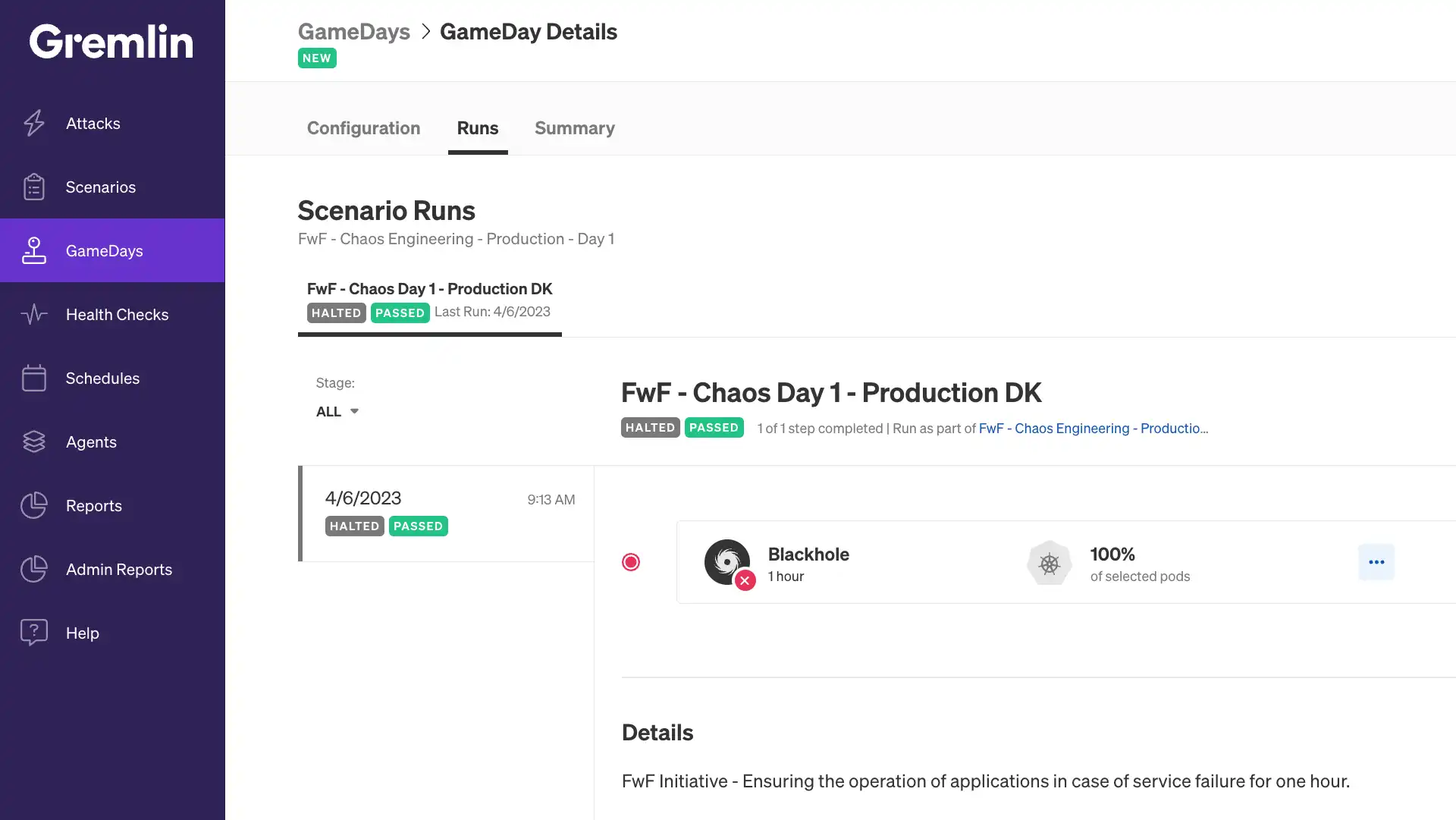
Para realizar os testes propostos, usamos a ferramenta de Chaos Engineering chamada Gremlin, que nos permitiu criar ataques blackhole.

O conceito de Blackhole, usado pelo Gremlin, refere-se a uma técnica que simula uma interrupção completa na comunicação entre os componentes de um sistema distribuído. Durante um ataque Blackhole, o Gremlin intercepta e descarta todo o tráfego de rede entre os serviços afetados, criando uma situação em que os componentes não podem se comunicar entre si, como se estivessem isolados em um buraco negro.
Usando essa abordagem, podemos interromper temporariamente a comunicação entre os serviços envolvidos, testando a resiliência do sistema e a capacidade de recuperação de falhas de comunicação. Essas suposições refletem problemas reais que foram encontrados na plataforma no passado, de modo que pudemos simular o incidente novamente e garantir que tudo funcionasse como deveria.
O método: Atingir o núcleo do sistema
Os testes do Chaos começaram a ser executados em ambientes controlados. Foram seis testes em ambientes de desenvolvimento, simulando o cenário que teríamos em produção. Essa etapa foi necessária para que pudéssemos minimizar o raio de explosão e garantir que o monitoramento fosse adequado para que nenhum detalhe passasse despercebido.
Ao longo do experimento, introduzimos uma série de ataques conhecidos como Blackhole em momentos diferentes e de forma controlada. Isso nos permitiu observar como cada aplicativo, que dependia do serviço atacado, se comportava quando ocorria uma interrupção.
Também conseguimos entender quais serviços tinham dependências ocultas desse serviço, bem como os gargalos que a falta de serviço poderia causar nos aplicativos. Essa abordagem nos ajudou a identificar pontos fracos e áreas de melhoria no sistema.
Os resultados: Revelação de segredos ocultos
No final do experimento, chegamos a algumas conclusões surpreendentes. Descobrimos que, embora o aplicativo de gerenciamento de sinalização de recursos fosse robusto em muitos aspectos, algumas áreas específicas precisavam de atenção. Identificamos problemas reais antes que eles se tornassem incidentes, o que poderia resultar em pedidos perdidos.
Entre os problemas encontrados, podemos citar a aplicação de patches que coletam novas métricas visando à observabilidade, a correção de bugs relacionados ao aumento da latência e a falta de configuração válida em caso de falha na obtenção do sinalizador de recurso. Além disso, os experimentos trouxeram melhorias na comunicação entre serviços internos de terceiros, proporcionando maior resiliência ao sistema como um todo, incluindo formas de contornar falhas em um cenário real.
Conclusão - O futuro: Desbravando novos caminhos
Essa experiência nos permitiu demonstrar o poder da Chaos Engineering na identificação e resolução de problemas antes que eles possam afetar negativamente os usuários finais, além de garantir que o monitoramento de problemas seja adequado e que a equipe saiba o que fazer quando ocorrer um problema relacionado. Isso nos permite pensar proativamente, identificando falhas antes mesmo da ocorrência de um incidente, e não mais sermos reativos aos problemas durante uma mudança.
Para nossas equipes, o experimento nos deu uma melhor compreensão do comportamento do serviço e de como podemos aprimorar nossos aplicativos para solucionar bugs desconhecidos, sem perdas. Com base em uma pesquisa interna realizada após o teste de produção, fica evidente que a maioria dos entrevistados considerou os experimentos de engenharia do caos eficazes na descoberta de possíveis pontos fracos ou vulnerabilidades do sistema.
60% indicaram que foram muito eficazes e 20% indicaram que foram extremamente eficazes. Além disso, 80% dos entrevistados concordaram que as etapas e os procedimentos do experimento de chaos engineering foram comunicados e fáceis de seguir.
Os participantes também expressaram interesse em se aprofundar no Chaos Engineering em suas respectivas equipes. Todos os participantes indicaram que pretendem realizar experimentos em um futuro próximo como parte do ciclo de vida do aplicativo.